Recently, I was confused about why a model was named U-Net and not something more relevant, and why the letter “U” was chosen.
Well, I went through the paper and this architecture explains it all:
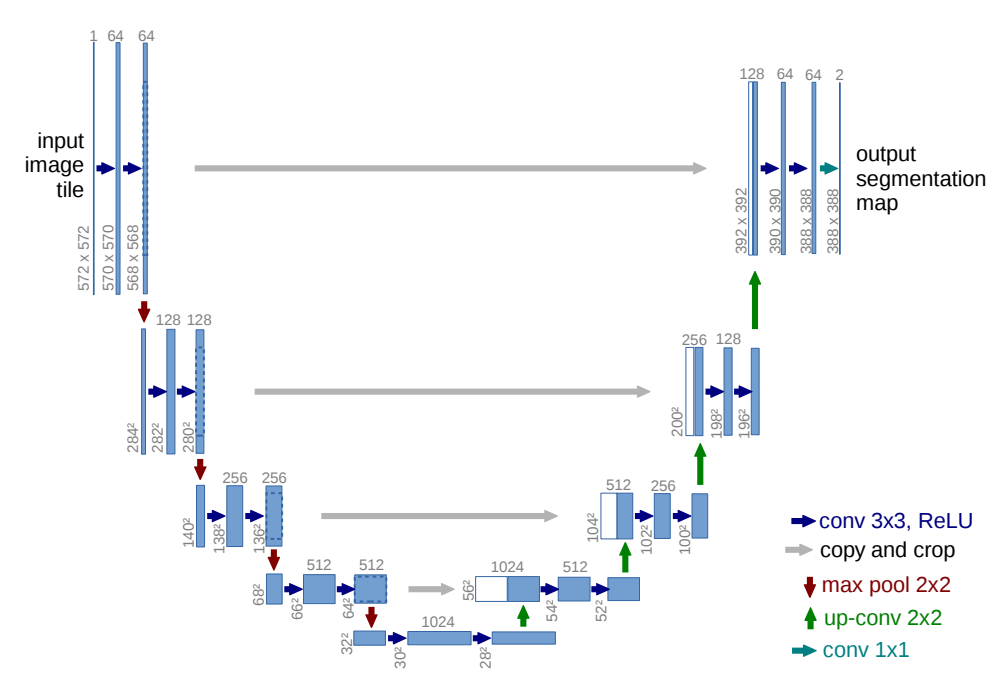
Let me break it down for you:
This architecture was initially proposed for medical image analysis where we need high-resolution input and output. Tasks include image segmentation, upscaling, masking, and even diffusion models.
The more U-Nets we stack, the higher resolution images we get.
So why is this model so effective when working with high-resolution inputs and outputs?
Well, the U-Net consists of an encoder and a decoder where the encoder is responsible for extracting features from the input image and the decoder is responsible for upscaling the output.
Encoder
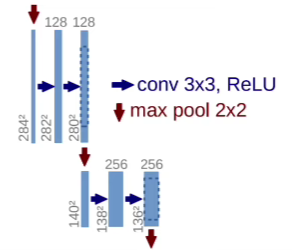
- Repeated 3x3 conv layers and ReLU layers
- 2x2 max pooling layers to downsample
- Double channels with conv after max pool
Decoder
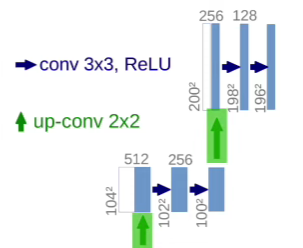
- Repeated 3x3 conv layers + ReLU layers
- Upsampling, followed by 2x2 conv layer
- Halve channels after upsampling conv
What happens between these two?
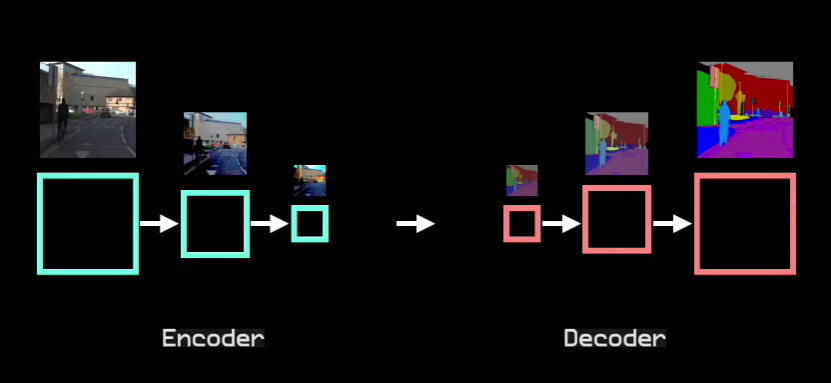
They have connecting paths which integrate both the encoder’s and the decoder’s features. The decoder has the semantic information and the encoder has more spatial information, and by combining both, we have a picture-perfect representation.
The Bottleneck
- Downsample with 2x2 max pooling
- Repeated 3x3 convolutional layers + ReLU
- Double channels with conv after max pool
- Upsample followed by a 2x2 convolution
And that’s all! If you want to know more in detail and understand all the mathematical stuff, read through the U-Net paper: https://arxiv.org/abs/1505.04597