Language models are amazing but they’re not magic. They generate responses based on patterns learned during training, which means they’re limited to the data they’ve seen. That leads to three common problems: outdated facts, domain-specific gaps, and the dreaded hallucinations confident-sounding but incorrect answers.
Enter RAG: Retrieval-Augmented Generation. Think of it as giving the model a smart librarian. Instead of forcing the model to guess from its limited knowledge, RAG fetches relevant documents at query time and feeds them into the model as context. The result: answers that are more accurate, up-to-date, and grounded in real sources.
How RAG works (high-level)
- Query: a user asks something.
- Retrieve: a retrieval system (usually using embeddings + a vector database) finds semantically related documents.
- Augment: those documents are appended to the prompt as context.
- Generate: the LLM consumes the augmented prompt and produces a grounded answer.
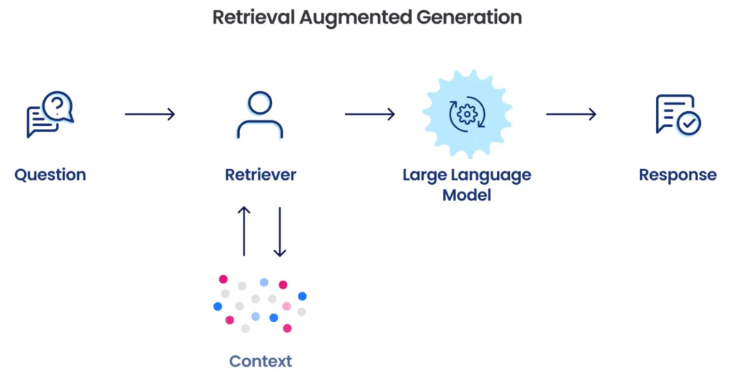
Why it matters: instead of inventing facts, the model can cite or rely on documents that actually contain the needed information. This is why RAG is being used in knowledge bases, enterprise search, customer support bots, and any system that needs factual accuracy.
Prompt engineering, fine-tuning, and RAG
People often ask whether to prompt-engineer or fine-tune a model. RAG sits beside those tools — it complements them. Prompt engineering nudges the model’s behavior, fine-tuning changes its weights permanently, and RAG supplies external signals at runtime. For many tasks where the knowledge evolves frequently, RAG is the most cost-effective way to keep answers current.
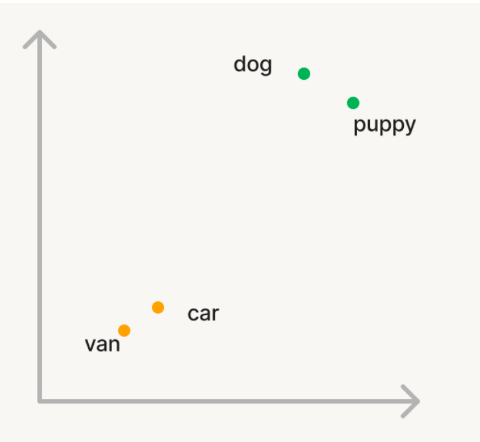
So what is this vector space i keep talking about?
In vector search, documents and queries are converted into numeric vectors (embeddings) by a model. Semantically similar texts map to nearby points in that high-dimensional space. For example, the vectors for “dog” and “puppy” sit close together, while “dog” and “car” are further apart.
This lets you find related documents by looking for vectors that are near the query vector no brittle keyword lists required.
How we measure similarity?
Cosine similarity is the most common metric: it measures the cosine of the angle between two vectors, giving a value from -1 (opposite) to 1 (identical). In practice, you pick documents with the highest cosine score to pass as context to the LLM.
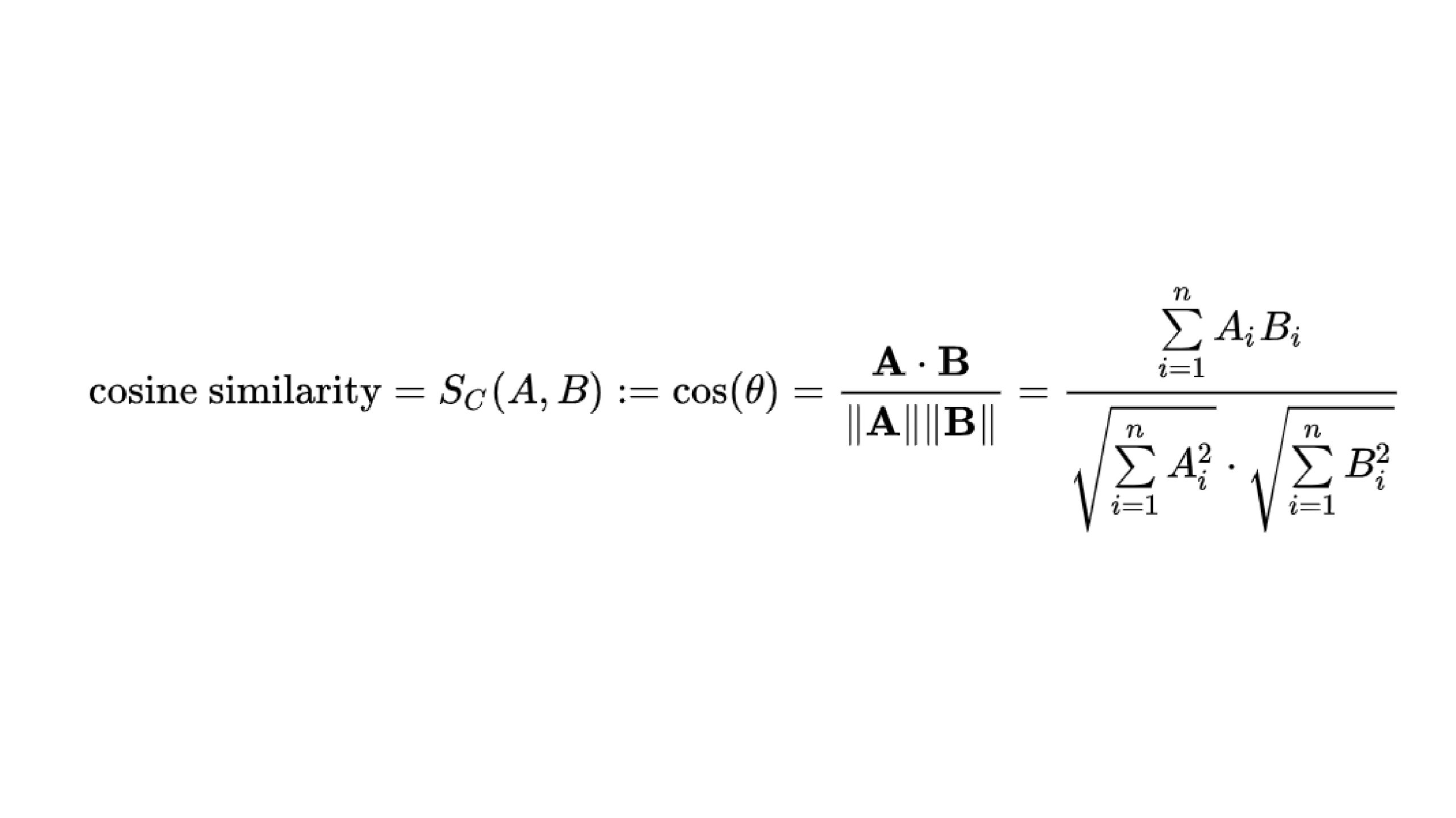
Putting it together
RAG is powerful because it blends retrieval and generation: retrieval gives you relevant, grounded facts; generation composes them into readable answers. Want a bot that cites your docs, knows the latest company policy, or summarizes support tickets? RAG is your friend.
Also a fact: Your Favourite Research LLM “Perplexity” runs completely on these terms giving you trusted sources from all corners of the world