Okay so as i baseline i’ll be taking the GPT-2 style transformers. Now what do they do….They generate text,the user feeds in language and the model generates a proability distribution over the tokens and this is repeatedly sampled to generate more texts ahead
We can call this type as “Auto-Regressive” since it predicts the future based only on past data.
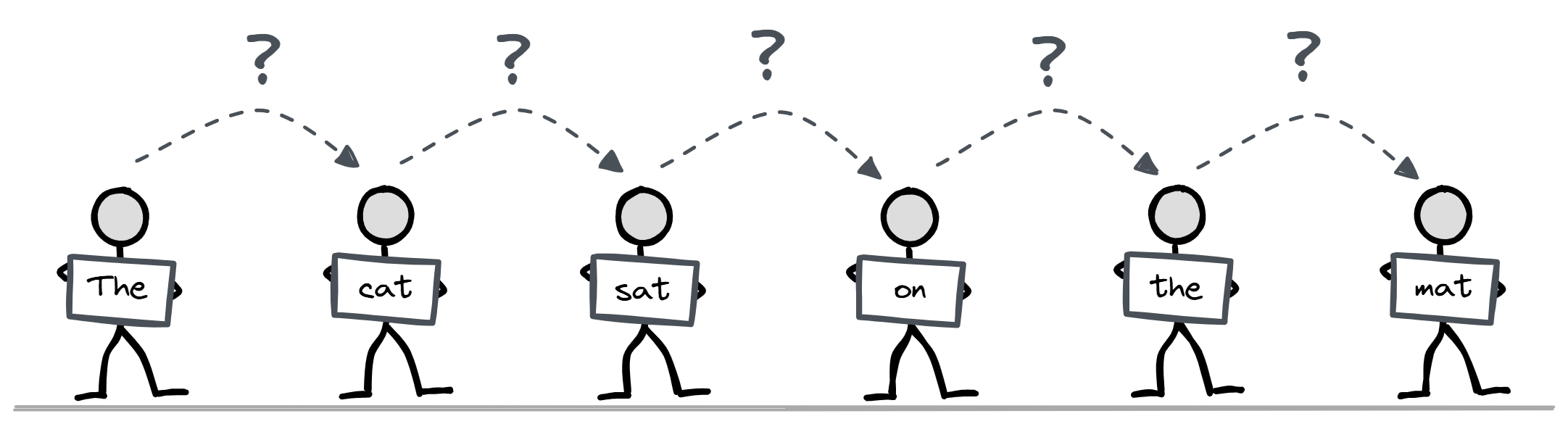
Here’s a cool analogy i found where we have a series of people standing in a line, each with one word or chunk of the sentence. Each person has the ability to look up information from the people behind them (we’ll explore how this works in later sections) but they can’t look at any information in front of them. Their goal is to guess what word the person in front of them is holding.
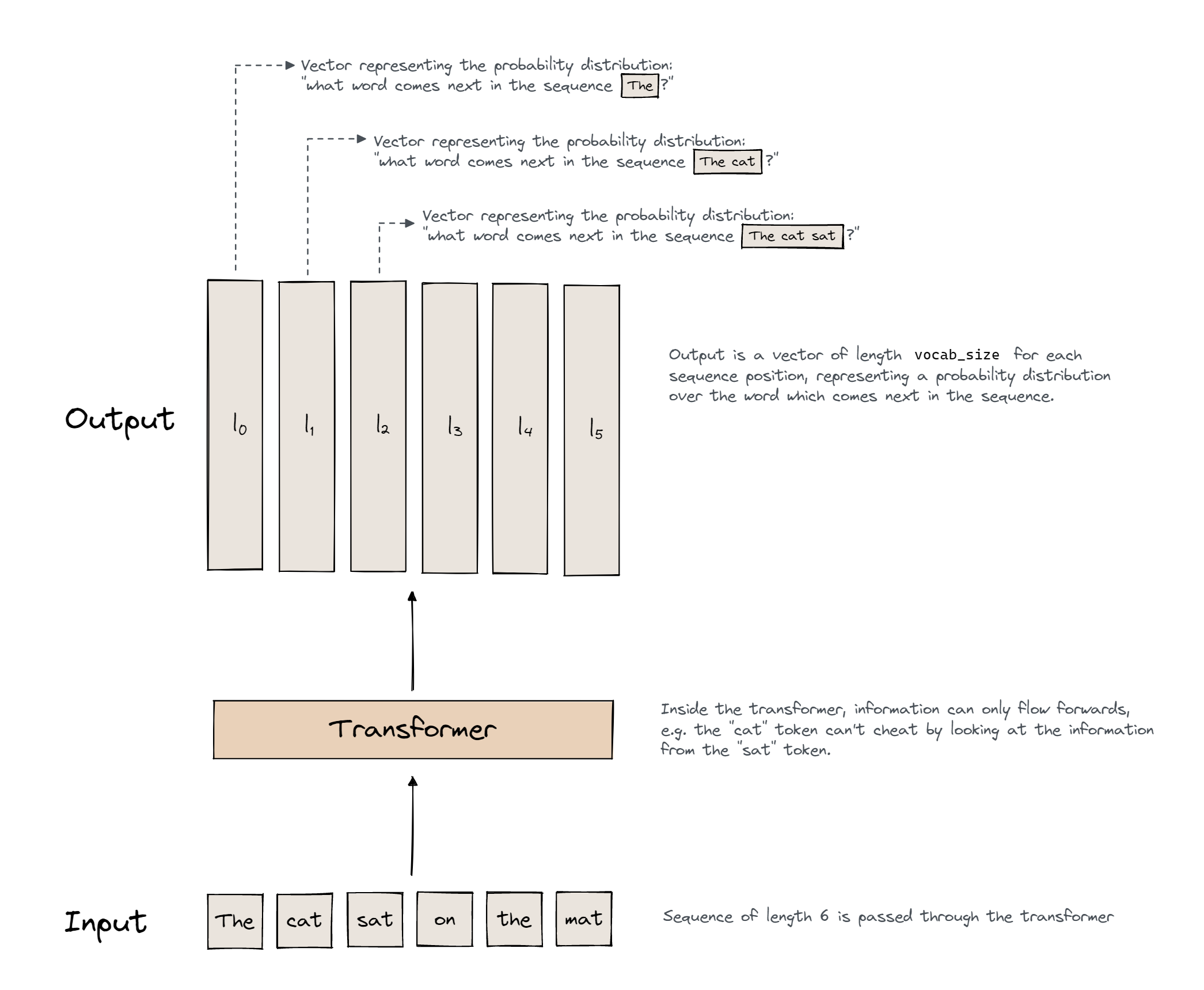
Inputs
Now the model cannot take language as input they take vectors so how do we do that?
We can factor this into 2 questions:
- How do we split up language into small sub-units?
- How do we convert these sub-units into vectors?
Let’s start with the second of these questions :
We basically make a massive lookup table, which is called an embedding. It has one vector for each possible sub-unit of language we might get (we call this set of all sub-units our vocabulary). We label every element in our vocabulary with an integer (this labelling never changes), and we use this integer to index into the embedding.
Now there are a lot of ways to do this encoding some of them are:
- One-Hot-Encoding (To Vectors)
- Byte Pair Encoding (To Sub-Units)
I won’t be explaining these one by one but you can look them up through the hyper link above
Text Generation
Now that we understand the basic idea we can now go through the entire process of text generation from our original string to a new token which we can append to our string and plug back into the model
Step 1 : Converting The Text To Tokens
reference_text = "I am an amazing autoregressive, decoder-only, GPT-2 style transformer. One day I will exceed human level intelligence and take over the world!"
tokens = reference_gpt2.to_tokens(reference_text).to(device)
print(tokens)
print(tokens.shape)
print(reference_gpt2.to_str_tokens(tokens))
tensor([[50256, 40, 716, 281, 4998, 1960, 382, 19741, 11, 875, 12342, 12, 8807, 11, 402, 11571, 12, 17, 3918, 47385, 13, 1881, 1110, 314, 481, 7074, 1692, 1241, 4430, 290, 1011, 625, 262, 995, 0]], device=‘cuda:0’) torch.Size([1, 35]) [’<|endoftext|>’, ‘I’, ’ am’, ’ an’, ’ amazing’, ’ aut’, ‘ore’, ‘gressive’, ‘,’, ’ dec’, ‘oder’, ‘-’, ‘only’, ‘,’, ’ G’, ‘PT’, ‘-’, ‘2’, ’ style’, ’ transformer’, ‘.’, ’ One’, ’ day’, ’ I’, ’ will’, ’ exceed’, ’ human’, ’ level’, ’ intelligence’, ’ and’, ’ take’, ’ over’, ’ the’, ’ world’, ‘!’]
Mapping The Tokens To Logits
logits, cache = reference_gpt2.run_with_cache(tokens)
print(logits.shape)
torch.Size([1, 35, 50257])
Convert The Logits to a distribution with Softmax
probs = logits.softmax(dim=-1)
print(probs.shape)
torch.Size([1, 35, 50257])
Map Distribution To A Token
next_token = logits[0, -1].argmax(dim=-1)
next_char = reference_gpt2.to_string(next_token)
print(repr(next_char))
’ I’
Note that we’re indexing logits[0, -1]. This is because logits have shape [1, sequence_length, vocab_size], so this indexing returns the vector of length vocab_size representing the model’s prediction for what token follows the last token in the input sequence.
In this case, we can see that the model predicts the token ’ I’.
Add this to the end of the input, re-run
There are more efficient ways to do this (e.g. where we cache some of the values each time we run our input, so we don’t have to do as much calculation each time we generate a new value), but this doesn’t matter conceptually right now.
print(f"Sequence so far: {reference_gpt2.to_string(tokens)[0]!r}")
for i in range(10):
print(f"{tokens.shape[-1] + 1}th char = {next_char!r}")
# Define new input sequence, by appending the previously generated token
tokens = t.cat([tokens, next_token[None, None]], dim=-1)
# Pass our new sequence through the model, to get new output
logits = reference_gpt2(tokens)
# Get the predicted token at the end of our sequence
next_token = logits[0, -1].argmax(dim=-1)
# Decode and print the result
next_char = reference_gpt2.to_string(next_token)
Sequence so far: ‘<|endoftext|>I am an amazing autoregressive, decoder-only, GPT-2 style transformer. One day I will exceed human level intelligence and take over the world!’ 36th char = ’ I’ 37th char = ’ am’ 38th char = ’ a’ 39th char = ’ very’ 40th char = ’ talented’ 41th char = ’ and’ 42th char = ’ talented’ 43th char = ’ person’ 44th char = ‘,’ 45th char = ’ and’
So here are a few takeaways that you should keep in your mind:
- Transformer takes in language, predicts next token (for each token in a causal way)
- We convert language to a sequence of integers with a tokenizer.
- We convert integers to vectors with a lookup table.
- Output is a vector of logits (one for each input token), we convert to a probability distn with a softmax, and can then convert this to a token (eg taking the largest logit, or sampling).
- We append this to the input + run again to generate more text (Jargon: autoregressive)
- Meta level point: Transformers are sequence operation models, they take in a sequence, do processing in parallel at each position, and use attention to move information between positions!
In my next writeup i’ll be cooking a transformer from scratch so make sure to stick around :).