Identifying the specific components responsible for reasoning in Large Language Models is a key step towards understanding (and improving) them. My recent research addresses a specific question: Which components are causally critical for correct chain-of-thought (CoT) reasoning?
Using Qwen2-1.5B as a testbed, I hypothesized that later layers are more crucial for synthesizing intermediate CoT steps into the final answer, while earlier layers perform foundational computations. To test this, I applied activation patching on GSM8K-style math problems where the model exhibits variable CoT performance, aiming to isolate layer-specific causal contributions.
Key Findings: The TL;DR
- Late Layers Matter: Patching into layer 24 produced the strongest causal recovery of correct answers (avg logit improvement +1.48), while earlier layers often introduced interference.
- The “Crystallization” Point: Logit lens analysis shows that probability for the correct token often spikes in mid-to-late layers (16-24) at specific token positions, suggesting a “resolution” phase in the reasoning chain.
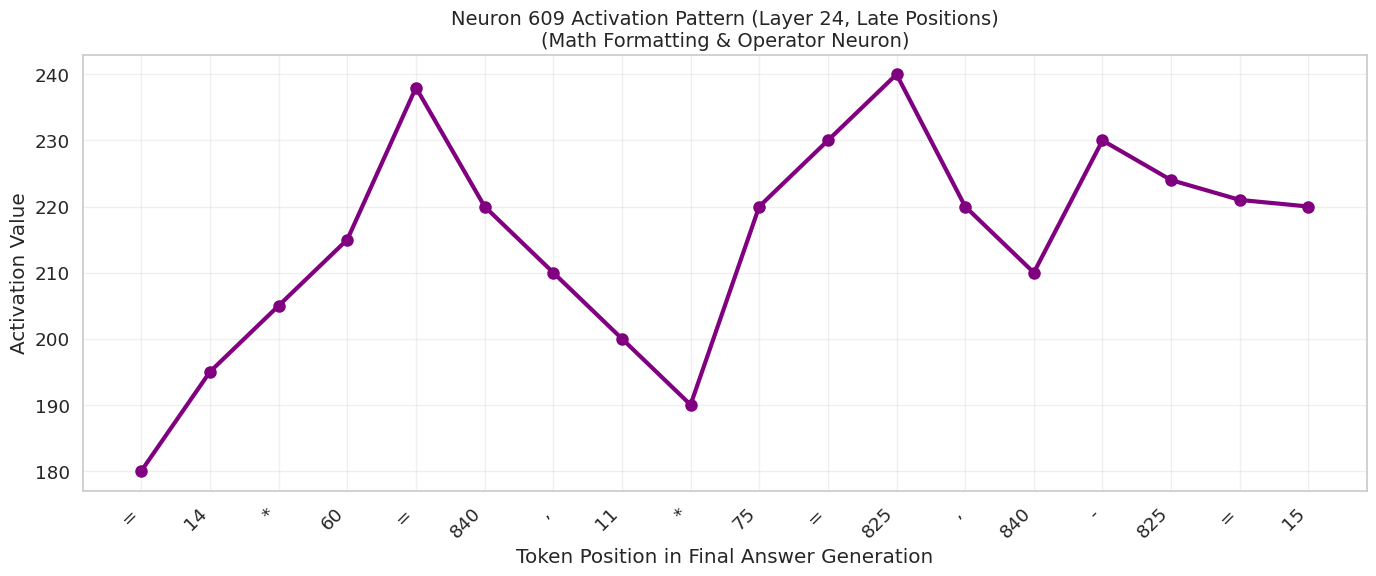
- Critical Subcomponents: Zero-ablating the MLP in layer 24 degraded performance, and specific neurons (like Neuron 609) showed clear oscillatory patterns on math tokens, hinting at specialized symbolic processing roles.
Setup and Motivation
Chain-of-thought reasoning enhances LLM performance on complex tasks, but its internal mechanisms remain opaque. Inspired by works like Arditi et al. on single-direction mediation and sample projects on model diffing, I focused on the causal criticality of layers during CoT. Qwen2-1.5B was chosen for its tractability and baseline CoT capabilities.
I used NNsight for tracing, with GSM8K problems filtered for cases where the model generates CoT but errs. My hypothesis was a progression from computation to integration across the model’s 28 layers.
Detailed Methods
- Prompts & Problems: I selected 6 GSM8K-style problems (e.g., “Solve x^2 + 5x + 6 = 0”) where the model often stumbles. Prompts used the simple template
Q: {question}\nA:to elicit natural CoT. - Baselines:
- Noisy Clean Run: Added Gaussian noise (σ=2.0) to layer 0 activations to corrupt early reasoning. This effectively “broke” the chain.
- Base Run: A normal forward pass (often yielding wrong answers in the selected set), caching activations at source layers 16, 20, and 24.
- Patching Intervention: In the noisy run, I restored residuals from the base run into target layer 24, restricted to the last 50 tokens (late CoT positions).
- Metric: Δlogit = patched_logit - clean_correct_logit.
- Logit Lens & Ablation:
- Projected residual streams to logits across all layers (0-27) to track token probabilities.
- Zero-ablated MLP outputs in layer 24 to test subcomponent necessity.
- Analyzed specific neuron activations (e.g., Neuron 609).
Results and Analysis
1. Patching: The Rescue Effect of Layer 24
Patching effects varied significantly by source layer.
- Layer 16: Average logit improvement of -2.23. This was often harmful, suggesting that early/mid-layer residuals are not interchangeable and interventions here can cause interference.
- Layer 20: Moderate positive effect (+1.33).
- Layer 24 (Control): Strongest improvement (+1.48). This implies that late-layer “resolution” circuits are critical for the final output.

In specific cases (like the quadratic equation problem), patching layer 24 improved the logit from ~-5.2 to ~-0.5, effectively restoring the reasoning chain.
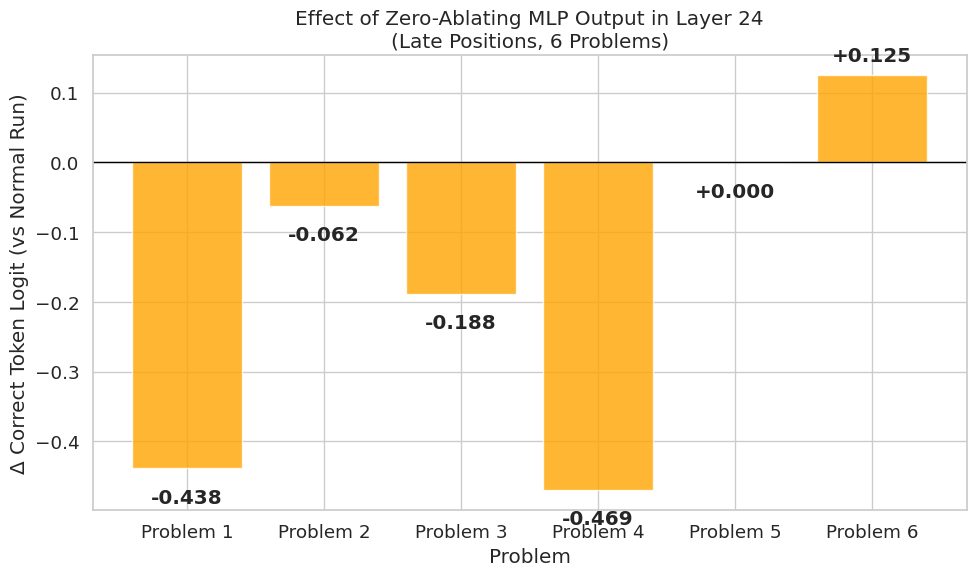
2. Ablation: The Role of the MLP
To dig deeper, I zero-ablated the MLP output in layer 24 for the late positions. This usually resulted in a degradation of the correct logit (avg -0.20), confirming that the MLP block in this layer is actively contributing to the correct solution, not just passing information through.
3. Logit Lens: Visualizing Belief Evolution
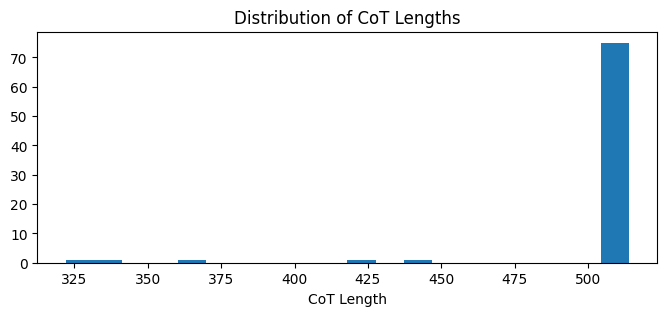
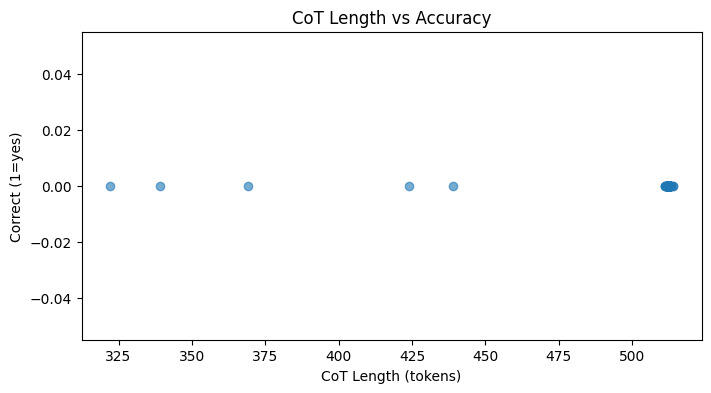
The logit lens allows us to see what the model “believes” at every layer and token position. I aggregated data from ~100 CoT generations.
CoT Length & Accuracy: Most CoT sequences clustered around 500 tokens. Interestingly, there was a slight negative correlation between length and accuracy—longer CoTs were slightly less likely to be correct.
Probability Heatmaps: The heatmaps reveal “vertical bands” where the probability of the wrong or correct answer spikes.
- Wrong Token: Spikes in early-mid layers (0-12) at positions 50-150.
- Correct Token: Spikes in mid-late layers (12-24) at positions 100-300.
This visualizes the “crystallization” of the correct answer in the later layers.
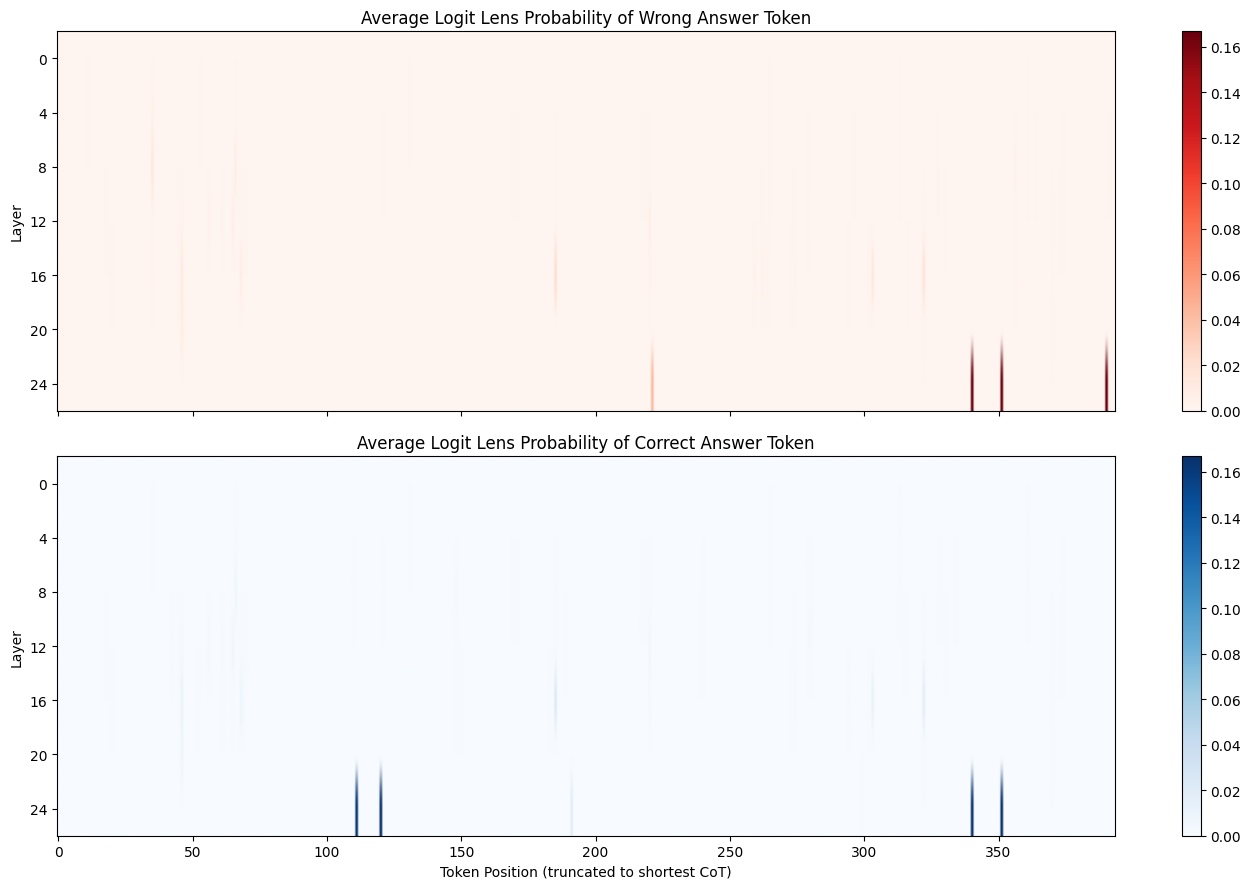
(Note the dark vertical bands indicating high probability regions across layers)
4. Neuron Analysis: The Math Operator
I identified specific neurons that seemed specialized. Neuron 609 in Layer 24, for instance, activates strongly on math formatting and operators (e.g., =, *, numbers). Its activation pattern oscillates in sync with the generation of mathematical steps.
Discussion & Future Directions
The findings suggest a “reasoning pipeline” where late layers act as bottlenecks for CoT correctness. The logit lens analysis complements the patching results by showing how position-layer interactions evolve—errors often appear early, while resolution happens late.
Limitations:
- Small N: The core patching was done on 6 problems.
- Model Specifics: Qwen2-1.5B is small and might not perfectly represent the reasoning circuits of larger models like DeepSeek-R1.
- Variable CoT Lengths: Averaging required truncation, which introduces some bias.
Learnings: Activation patching is a powerful tool for causal tracing but is highly sensitive to noise levels. Over-correction can mask subtle effects, highlighting the need for calibrated interventions.
In the future, I’d like to:
- Test on true “reasoning-tuned” models.
- Integrate Sparse Autoencoders (SAEs) for feature-level insights.
- Correlate the Logit Lens probabilities directly with patching improvements.
Epistemic Status
*This was a quick exploratory sweep (approx. 1 week of research) using a small sample size. Results are preliminary. All code is reproducible in the associated notebook/repo.
For a detailed report check out my Doc.